
domingo, 31 de mayo de 2015
Prueba RESET de Ramsey (I)
sábado, 30 de mayo de 2015
El estadístico d de Durbin-Watson una vez más (IV)
viernes, 29 de mayo de 2015
El estadístico d de Durbin-Watson una vez más (III)
1. A partir de un modelo supuesto, obténgase los residuales MCO.
2. Si se cree que el modelo supuesto está mal especificado porque excluye una variable explicativa relevante, por ejemplo, Z, ordénese los residuales obtenidos en el paso 1 de acuerdo con los valores crecientes de Z. Nota: La variable Z podría ser una de las variables X incluidas con el modelo supuesto o podría ser algún tipo de función de esa variable. tal como X² o X³.
3. Calcúlese el estadístico d con los residuales así ordenados mediante la fórmula d usual, a saber.
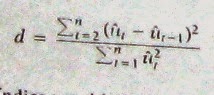
4. Con base en las tablas de Durbin-WAtson, si el valor d estimado es significativo, entonces se puede aceptar la hipótesis de mala especificación del modelo. Si ese resulta ser el caso, las medidas remediables surgirán naturalmente por si mismas.
jueves, 28 de mayo de 2015
El estadístico d de Durbin-Watson una vez más (II)


miércoles, 27 de mayo de 2015
El estadístico d de Durbin-Watson una vez más (I)
martes, 26 de mayo de 2015
Examen de los residuos (II)
La utilidad de examinar la gráfica de residuales es entonces clara: Si hay errores de especificación, los residuales presentarán patrones distinguibles.
lunes, 25 de mayo de 2015
Examen de los residuos (I)
Para ilustrar, reconsidérese la función cúbica del costo total de producción analizada en el cap 7. Supóngase que la verdadera función de costo total se describe de la siguiente manera, donde Y = costo total y X = producción.
-

domingo, 24 de mayo de 2015
Pruebas sobre variables omitidas y forma funcional correcta
En la práctica, nunca se está seguro de que el modelo adoptado para pruebas empíricas sea "el verdadero, total la verdad y nada más que la verdad". Con base en la teoría o en la introspección y en el trabajo empírico previo, se desarrolla un modelo, el cual se cree que recoge la esencia del tema en estudio. Luego, el modelo se somete a una prueba empírica. Después de obtener los resultados, se inicia el "post mortem", teniendo en mente los criterios de un buen modelo estudiados anteriormente. Es en esta etapa cuando se viene a saber si el modelo seleccionado es adecuado. Al determinar la bondad de ajuste del modelo, se observan algunas características generales de los resultados, tales como el valor R², las razones t estimadas, los signos de los coeficientes estimados en relación con sus expectativas previas, el estadístico Durbin-Watson y similares. Si estos diagnósticos son razonablemente buenos, puede proclamarse que el modelo seleccionado es una buena representación de la realidad. Mediante el mismo procedimiento, si los resultados no aparecen estimulantes porque el valor de R² es muy bajo o porque muy pocos coeficientes son estadísticamente significativos o tienen los signos correctos o debido a que el d de Durbin-Watson es muy bajo, entonces puede empezar a preocupar la bondad del ajuste del modelo y se puede empezar a buscar remedios: Tal vez se ha omitido una variable importante, o se ha utilizado la forma funcional equivocada o no se ha realizado la primera diferenciación de la serie de tiempo (para eliminar la correlación serial) y así sucesivamente. Como una ayuda para determinar si la inadecuabilidad del modelo se debe a uno o más de estos problemas, se pueden utilizar al grupo algunos de los siguientes métodos.
sábado, 23 de mayo de 2015
Nivel de significancia nominal vs. nivel de significancia verdadero en presencia de dat-mining (II)
Por supuesto, en la práctica los investigadores informan solamente los resultados finales, sin reconocer que llegaron a los resultados luego de una considerable data-mining. Posiblemente, una declaración en este sentido podría costarle al investigador la publicación de su trabajo y posiblemente un ascenso laboral y/o aun su posicion en la universidad!!
viernes, 22 de mayo de 2015
Nivel de significancia nominal vs. nivel de significancia verdadero en presencia de dat-mining (I)

jueves, 21 de mayo de 2015
Detección de la presencia de variables innecesarias

miércoles, 20 de mayo de 2015
Pruebas de errores de especificación
martes, 19 de mayo de 2015
Inclusión de una variable irrelevante (sobreespecificación de un modelo) (III)
Obsérvese la asimetría en los dos tipos de sesgos de especificación que se han considerado. Si se excluye una variable relevante, los coeficientes de las variables consideradas en el modelo son generalmente sesgados al igual que inconsistentes, la varianza del error es incorrectamente estimada y los procedimientos usuales de prueba de hipótesis se invalidan. Por otra parte, la inclusión de una variable irrelevante en el modelo proporciona aun estimaciones insesgadas y consistentes de los coeficientes en el modelo verdadero, la varianza del error es correctamente estimada y los métodos convencionales de prueba de hipótesis son aún válidos; la única penalización que se paga por la inclusión de la variable superflua es que las varianzas estimadas de los coeficientes son mayores y como resultado, las inferencias probabílisticas sobre los parámetros son menos precisas. Una conclusión no deseada aquí sería que es mejor incluir variables irrelevantes que omitir variables relevantes. Pero esta filosofia no es estricta puesto que la adición de variables inneesarias conducirá a una pérdida de eficiencia de los estimadores y puede llevar también al problema de la multicolinealidad. Por queé? para no mencionar la pérdida de grados de libertad. Por consiguiente
En general, el mejor enfoque es incluir solamente las variables explicativas que, teóricamente, influyan directamente sobre la variable dependiente y no hayan sido tenidas en cuenta en otras variables incluidas.
lunes, 18 de mayo de 2015
Inclusión de una variable irrelevante (sobreespecificación de un modelo) (II)


domingo, 17 de mayo de 2015

sábado, 16 de mayo de 2015
Omisión de una variable relevante (especificación insuficiente de un modelo) (VI)
viernes, 15 de mayo de 2015
Omisión de una variable relevante (especificación insuficiente de un modelo) (V)

jueves, 14 de mayo de 2015
Omisión de una variable relevante (especificación insuficiente de un modelo) (IV)

miércoles, 13 de mayo de 2015
Omisión de una variable relevante (especificación insuficiente de un modelo) (III)

martes, 12 de mayo de 2015
Omisión de una variable relevante (especificación insuficiente de un modelo) (II)
- Si la variable excluida X3 está correlacionado con la variable incluida X2, es decir r23 es diferente de cero, α1 y α2 son sesgados como también inconsistentes. Es decir, E(α1) no es igual a β1 y E(α2) no es igual a β2 e independientemente de qué tan grande sea la muestra, el sesgo no desaparece.
- Aun cuando X2 y X3 no estén correlacionados (r23 = 0), α1 es aun sesgado, aunque α2 sea ahora insesgado.
- La varianza de la perturbación σ² está incorrectamente estimada.
lunes, 11 de mayo de 2015
Omisión de una variable relevante (especificación insuficiente de un modelo) (I)

domingo, 10 de mayo de 2015
Consecuencias de los errores de especificación
sábado, 9 de mayo de 2015
Tipos de errores de especificación (V)
- Omisión de una variable relevante, véase (13.2.2)
- Inclusión de una variable innecesaria, véase (13.2.4)
- Adopción de la forma funcional equivocada, véase (13.2.6)
- Errores de medición, véase (13.2.7)
Antes de proceder, para empezar será conveniente saber la razón por la cual se pueden cometer tales errores. En algunos casos, se sabe cuál es el modelo correcto pero no es posible implementarlo porque los datos necesarios no están disponibles. Así, en el análisis de la función de consumo, algunos autores han argumentado que además del ingreso, es peciso incluir la riqueza del consumidor como variable explicativa. Sin embargo, las cifras sobre riqueza son bastante difíciles de obtener y por esta razón, esa variable frecuentemente se excluye del análisis. Otra razón consiste en que se puede saber qué variables deben incluirse en el modelo pero quizás no se sabe la forma funcional exacta en la cual deben aparecer las variables en el modelo: Son frecuentes los casos en los cuales la teoría no indica la forma funcional precisa del modelo; tampoco dirá si el modelo es lineal en las variables o lineal en los logaritmos de las variables, o alguna mezcla de las dos posibilidades, o si tendrá alguna otra forma. Finalmente y quizás lo más importante, con frecuencia un error de especificación realmente es un error por una mala especificación del modelo puesto que, en primer término, no se sabe cuál es el verdadero modelo. Se tratará este punto mas adelante.
viernes, 8 de mayo de 2015
Tipos de errores de especificación (IV)
Finalmente, considérese un investigador que utiliza el siguiente modelo:

jueves, 7 de mayo de 2015
Tipos de errores de especificación (III)

miércoles, 6 de mayo de 2015
Tipos de errores de especificación (II)

martes, 5 de mayo de 2015
Tipos de errores de especificación (I)

lunes, 4 de mayo de 2015
Poder de predicción.
domingo, 3 de mayo de 2015
Consistencia teórica
sábado, 2 de mayo de 2015
Bondad del Ajuste
viernes, 1 de mayo de 2015
Identificabilidad
